Aider blog
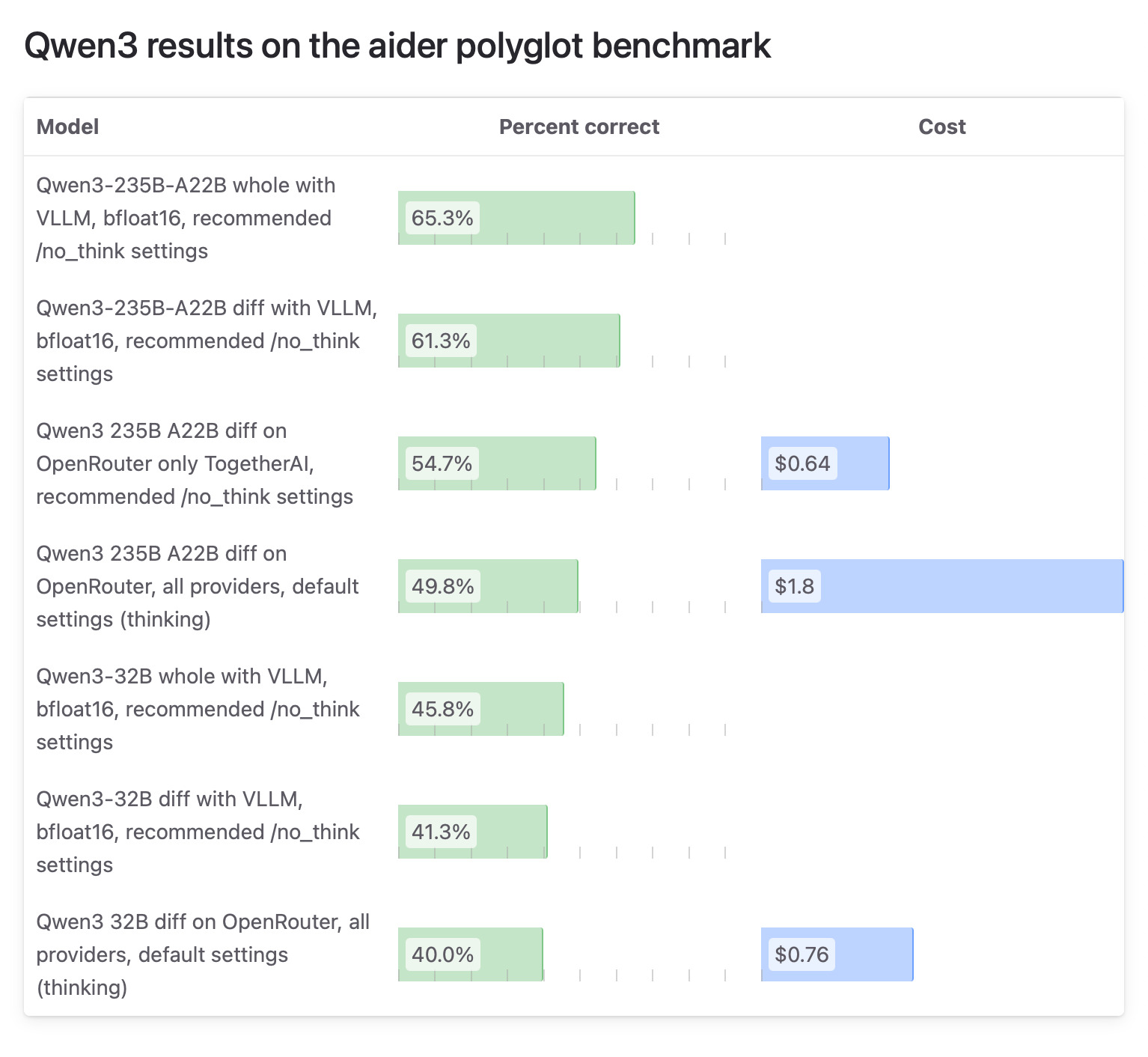
Qwen3 benchmark results
Benchmark results for Qwen3 models using the Aider polyglot coding benchmark.
[
](https://aider.chat/2025/05/08/qwen3.html)
MAY 8, 2025
Gemini 2.5 Pro Preview 03-25 benchmark cost
The $6.32 benchmark cost reported for Gemini 2.5 Pro Preview 03-25 was incorrect.
MAY 7, 2025
Alternative DeepSeek V3 providers
DeepSeek's API has been experiencing reliability issues. Here are alternative providers you can use.
JAN 28, 2025
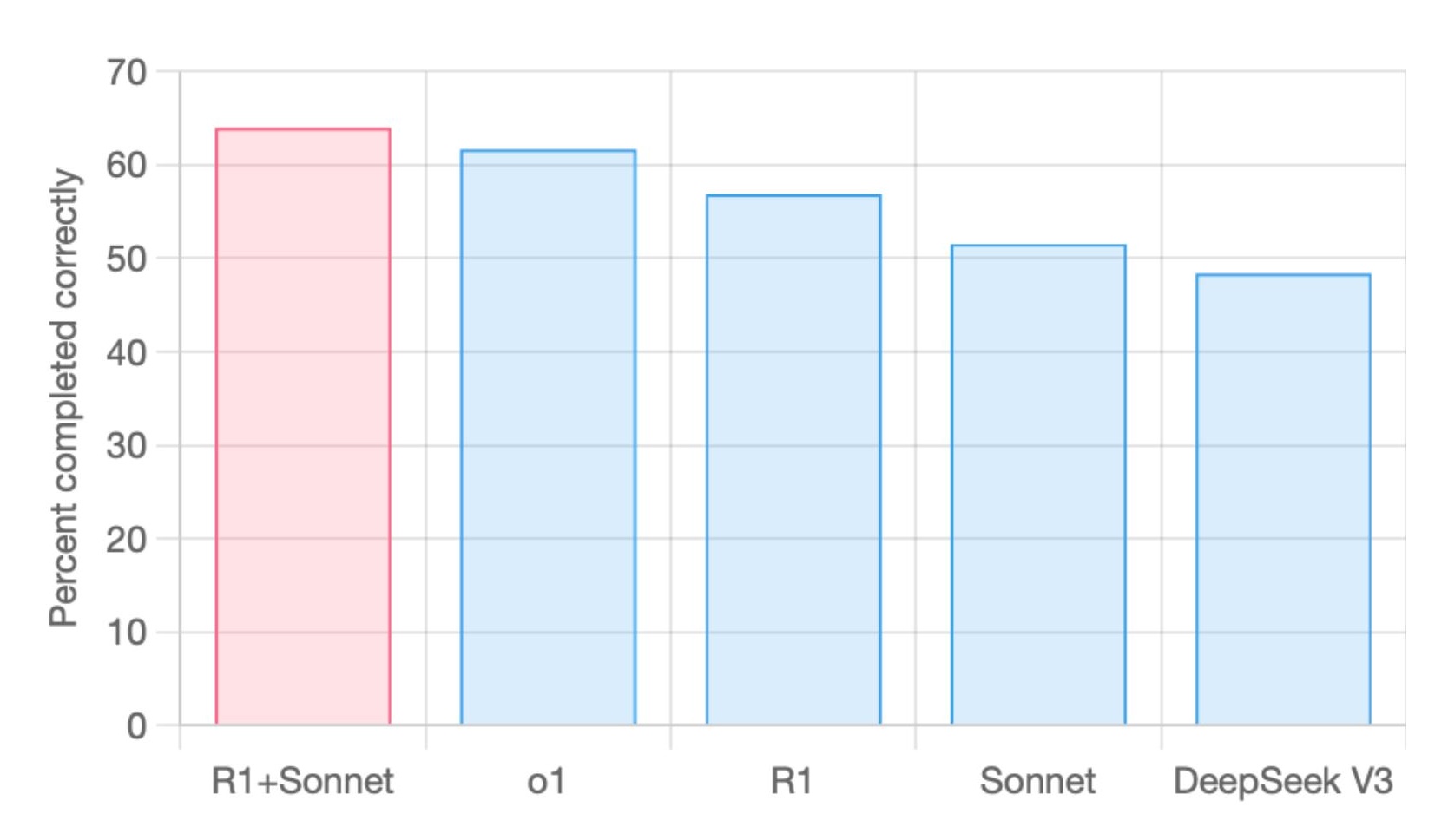
R1+Sonnet set SOTA on aider's polyglot benchmark
R1+Sonnet has set a new SOTA on the aider polyglot benchmark. At 14X less cost compared to o1.
[
](https://aider.chat/2025/01/24/r1-sonnet.html)
JAN 24, 2025
Using uv as an installer
Reliably packaging & distributing python CLI tools is hard. Aider uses uv in novel ways to make it easy to install the aider CLI, its dependencies and python 3.12. All in an isolated env.
JAN 15, 2025
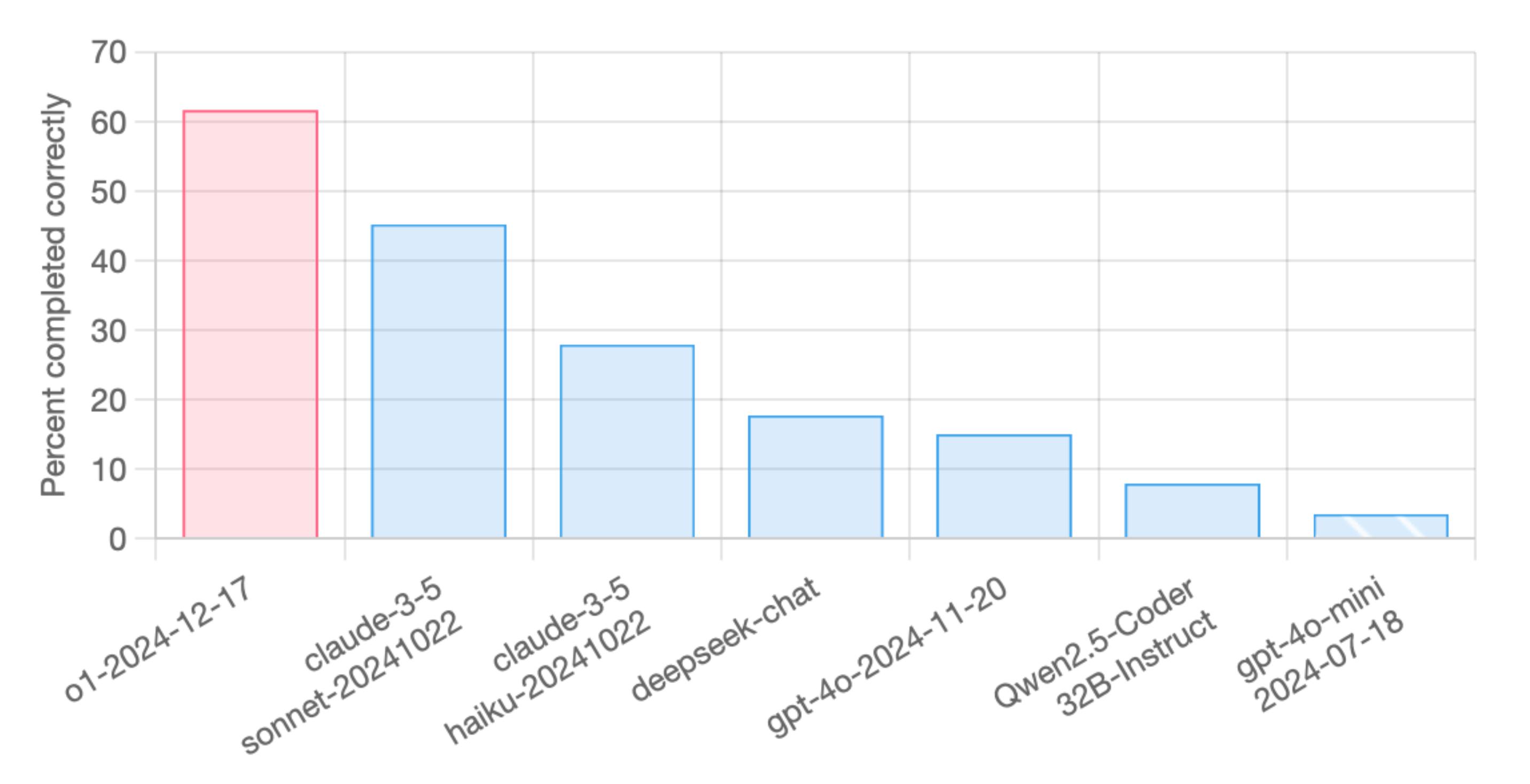
o1 tops aider's new polyglot leaderboard
o1 scores the top result on aider's new multi-language, more challenging coding benchmark.
[
](https://aider.chat/2024/12/21/polyglot.html)
DEC 21, 2024
QwQ is a code architect, not an editor
QwQ is reasoning model like o1, and needs to be used as an architect with another model as editor.
[

](https://aider.chat/2024/12/03/qwq.html)
DEC 3, 2024
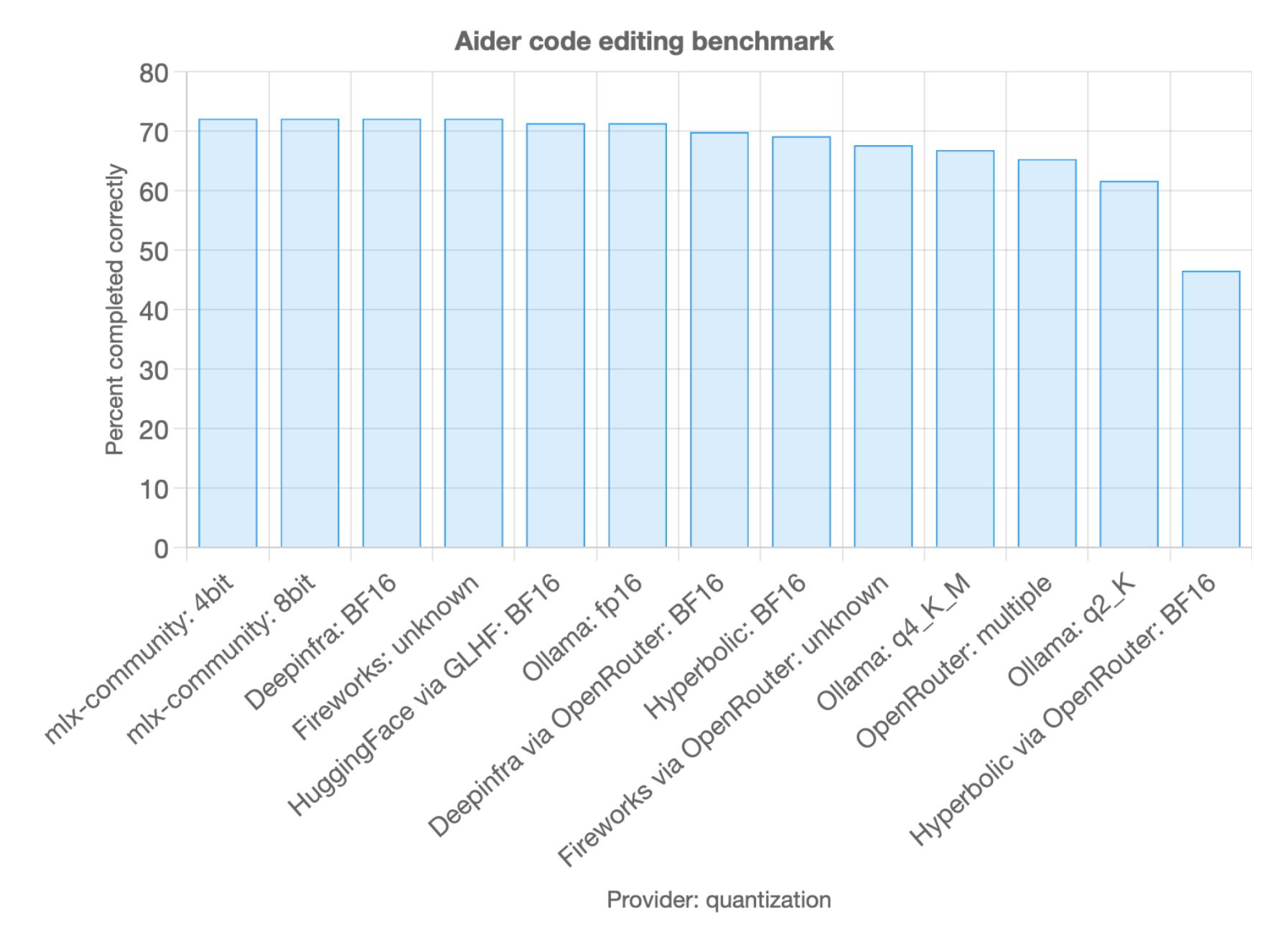
Details matter with open source models
Open source LLMs are becoming very powerful, but pay attention to how you (or your provider) are serving the model. It can affect code editing skill.
[
](https://aider.chat/2024/11/21/quantization.html)
NOV 21, 2024
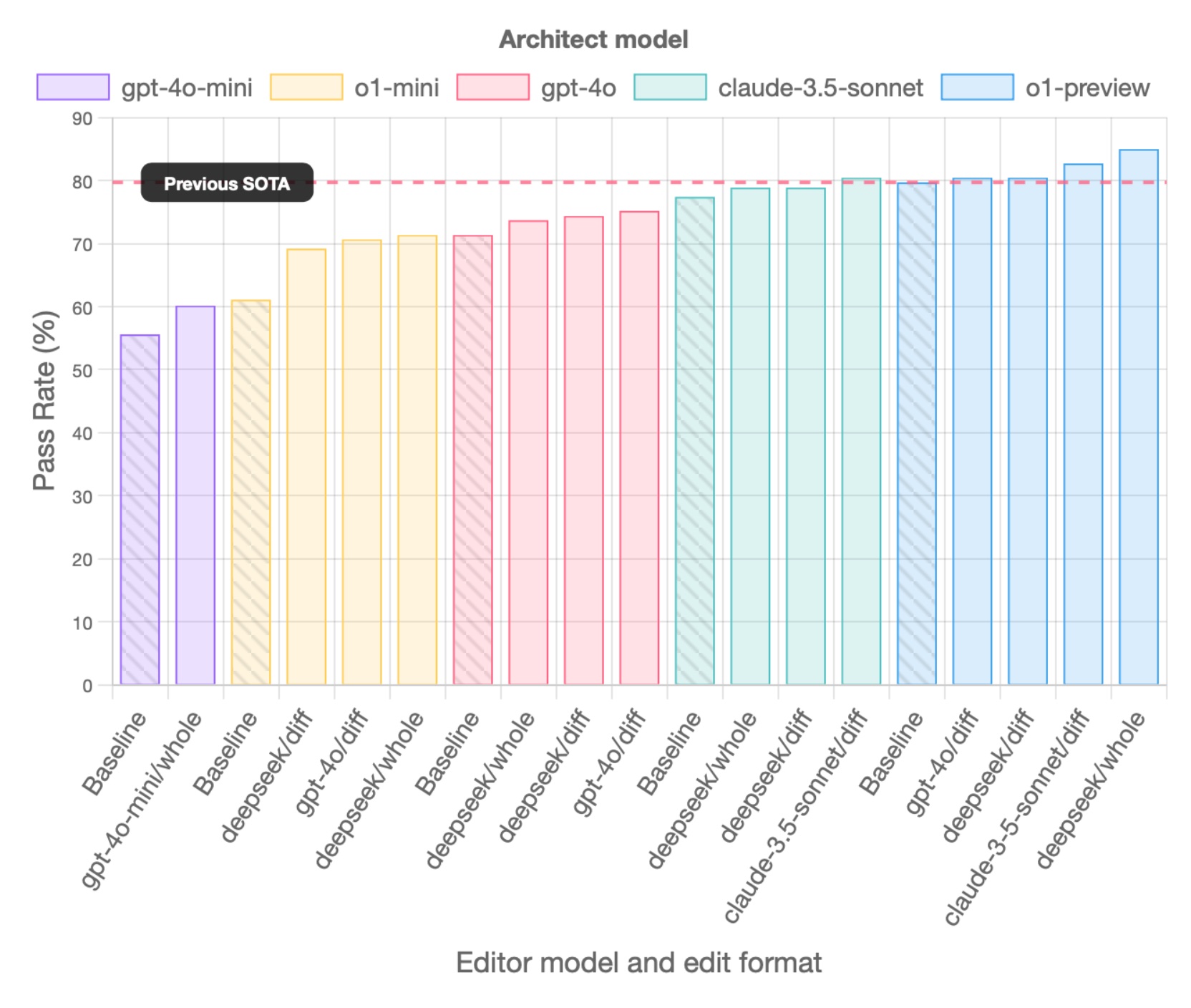
Separating code reasoning and editing
An Architect model describes how to solve the coding problem, and an Editor model translates that into file edits. This Architect/Editor approach produces SOTA benchmark results.
[
](https://aider.chat/2024/09/26/architect.html)
SEP 26, 2024
o1-preview is SOTA on the aider leaderboard
Preliminary benchmark results for the new OpenAI o1 models.
SEP 12, 2024
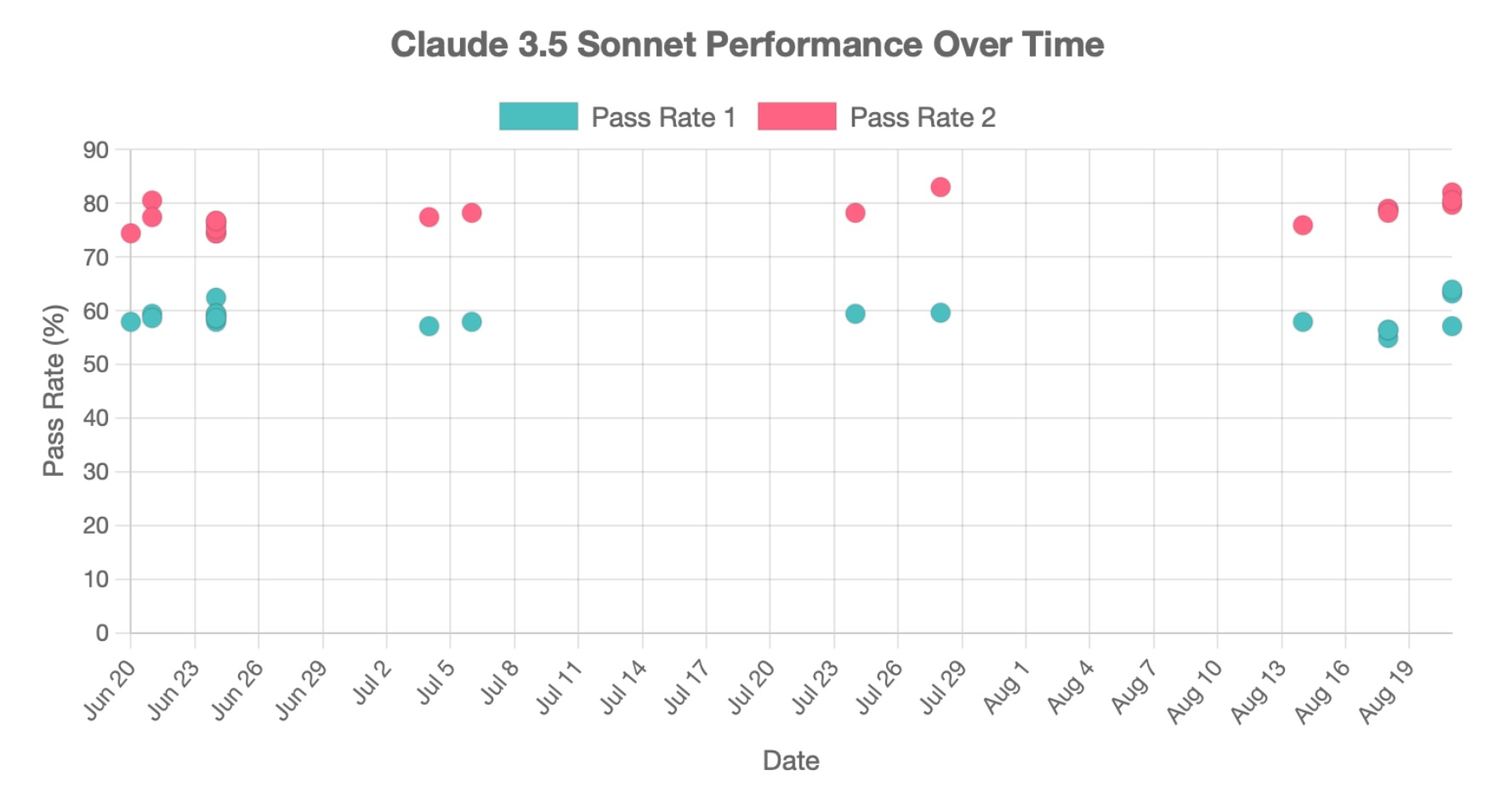
Sonnet seems as good as ever
Sonnet's score on the aider code editing benchmark has been stable since it launched.
[
](https://aider.chat/2024/08/26/sonnet-seems-fine.html)
AUG 26, 2024
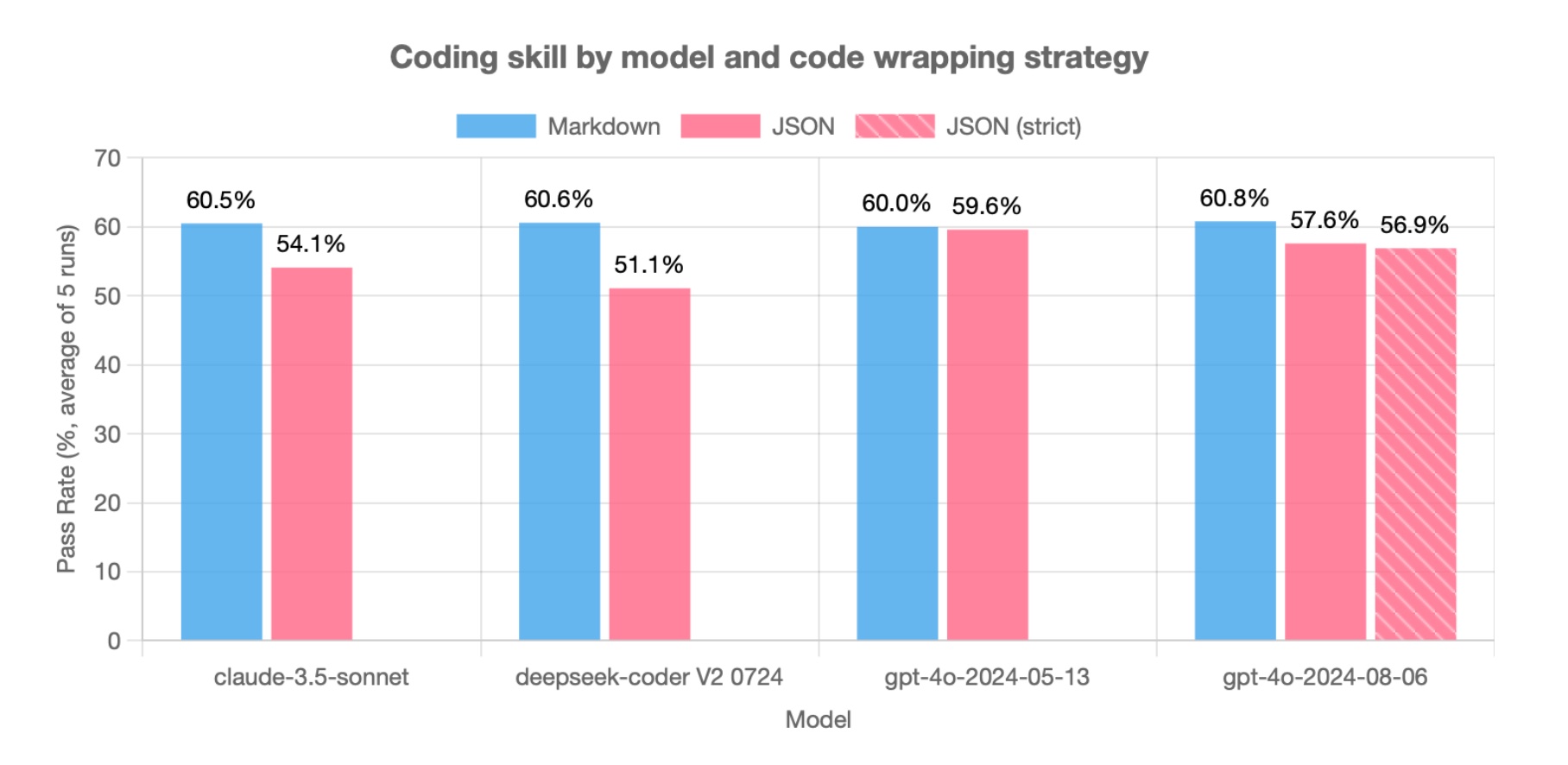
LLMs are bad at returning code in JSON
LLMs write worse code if you ask them to return the code wrapped in JSON via a tool function call.
[
](https://aider.chat/2024/08/14/code-in-json.html)
AUG 14, 2024
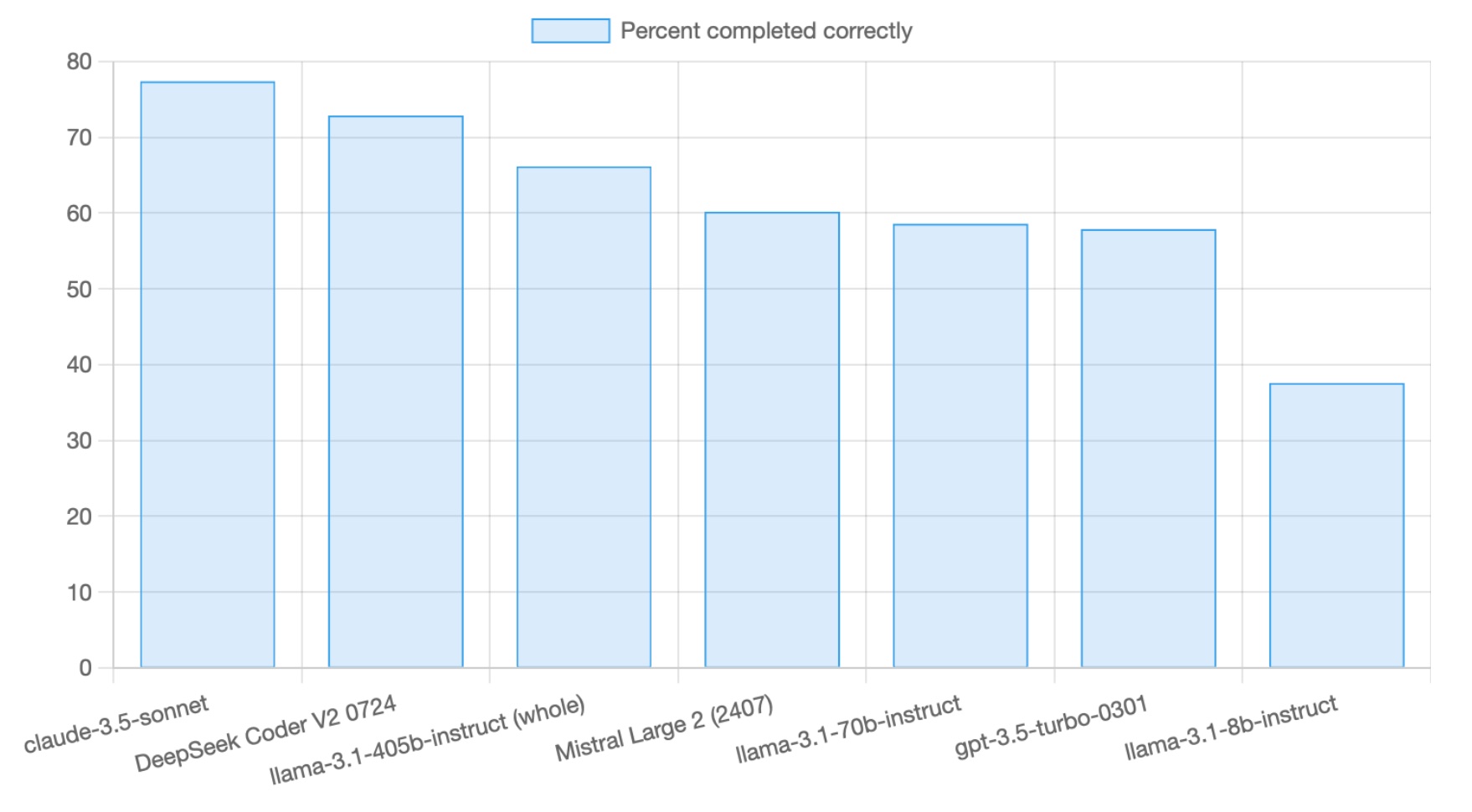
Coding with Llama 3.1, new DeepSeek Coder & Mistral Large
Summary of code editing skill for the new models, with Sonnet and GPT-3.5 for scale.
[
](https://aider.chat/2024/07/25/new-models.html)
JUL 25, 2024
Sonnet is the opposite of lazy
Claude 3.5 Sonnet can easily write more good code than fits in one 4k token API response.
[

](https://aider.chat/2024/07/01/sonnet-not-lazy.html)
JUL 1, 2024
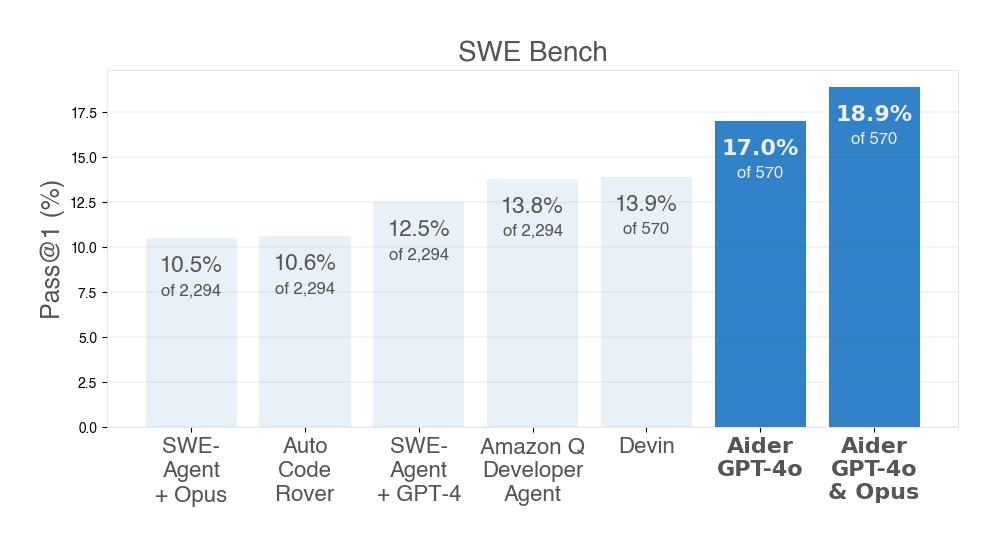
Aider is SOTA for both SWE Bench and SWE Bench Lite
Aider sets SOTA for the main SWE Bench, after recently setting SOTA for the Lite version.
[
](https://aider.chat/2024/06/02/main-swe-bench.html)
JUN 2, 2024
Aider has written 7% of its own code (outdated, now 70%)
This article is quite out dated. Aider is currently writing about 70% of the new code in each release.
[

](https://aider.chat/2024/05/24/self-assembly.html)
MAY 24, 2024
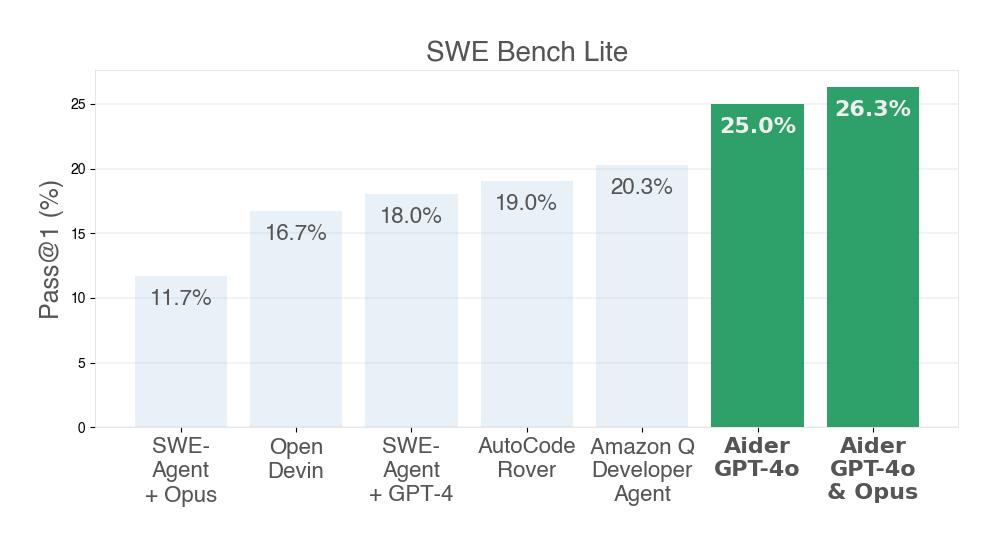
How aider scored SOTA 26.3% on SWE Bench Lite
Aider achieved this result mainly through its existing features that focus on static code analysis, reliable LLM code editing, and pragmatic UX for AI pair programming.
[
](https://aider.chat/2024/05/22/swe-bench-lite.html)
MAY 22, 2024
Linting code for LLMs with tree-sitter
Aider now lints code after every LLM edit and automatically fixes errors, using tree-sitter and AST-aware code context.
[

](https://aider.chat/2024/05/22/linting.html)
MAY 22, 2024
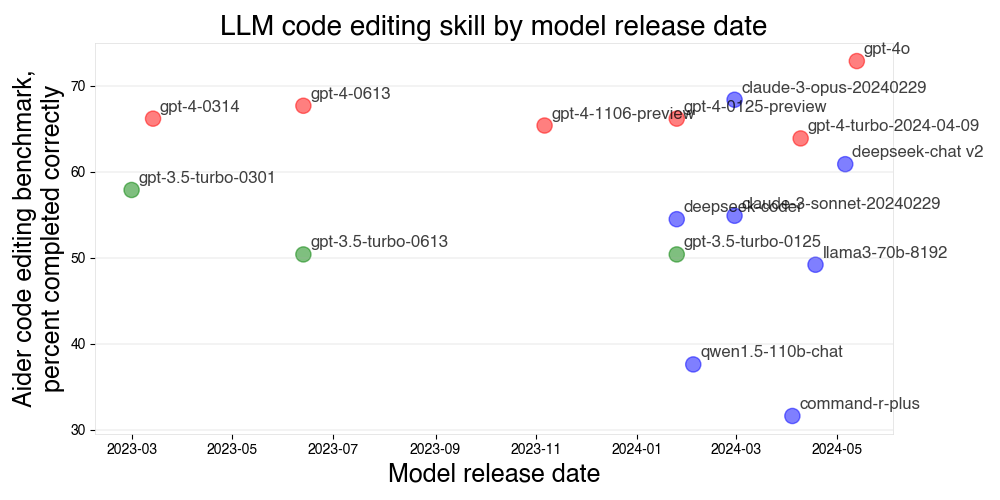
Drawing graphs with aider, GPT-4o and matplotlib
Use GPT-4o to draw graphs with matplotlib, including adjusting styles and making visual changes. You get the graph, but you also get the code in your repo.
[
](https://aider.chat/2024/05/13/models-over-time.html)
MAY 13, 2024
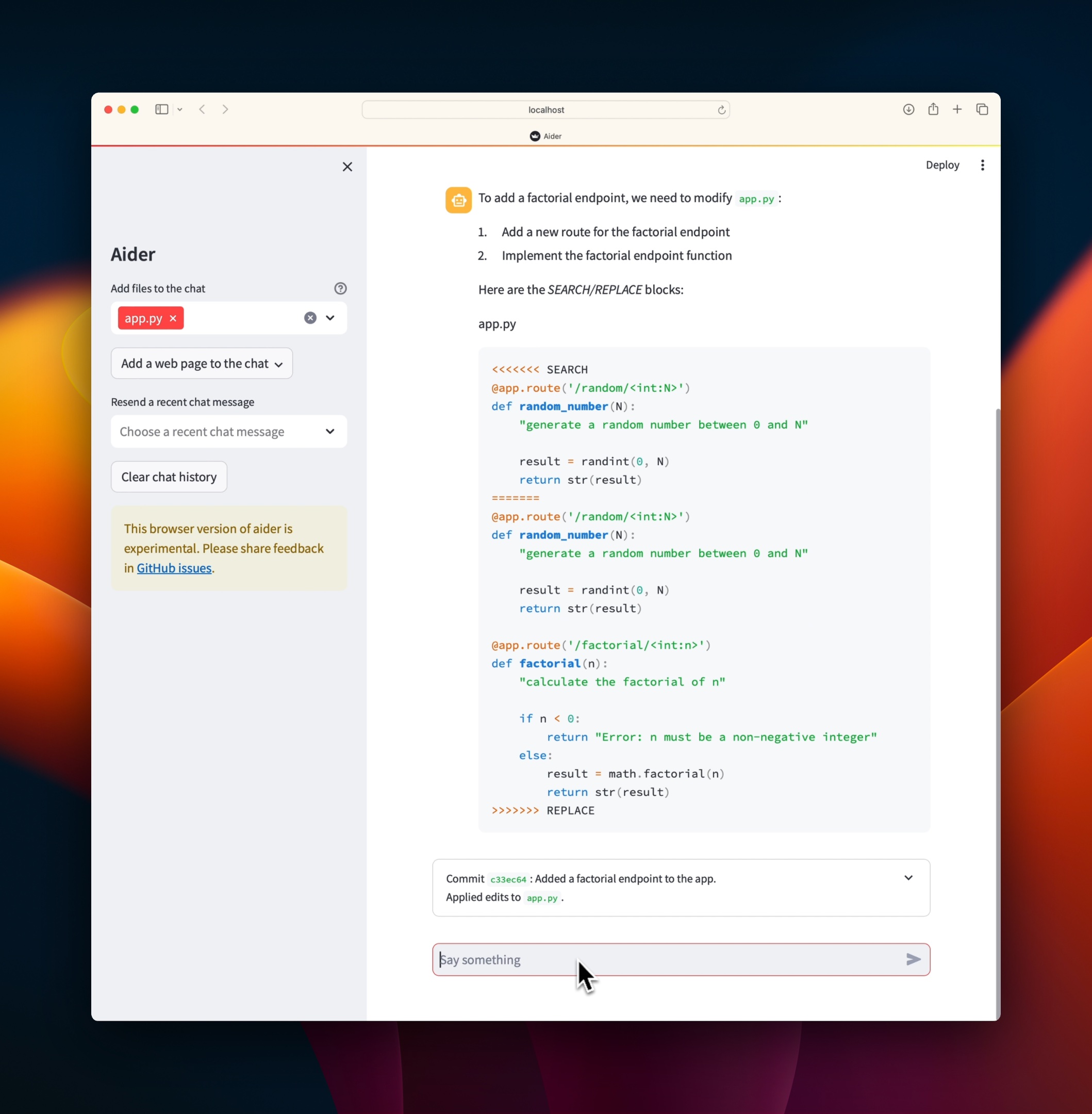
Aider in your browser
Aider has an experimental browser UI, allowing you to collaborate with LLMs on code in your local git repo.
[
](https://aider.chat/2024/05/02/browser.html)
MAY 2, 2024
GPT-4 Turbo with Vision is a step backwards for coding
OpenAI's GPT-4 Turbo with Vision model scores worse on aider's code editing benchmarks than all the previous GPT-4 models. In particular, it seems much more prone to "lazy coding" than the existing GPT-4 Turbo "preview" models.
[

](https://aider.chat/2024/04/09/gpt-4-turbo.html)
APR 9, 2024
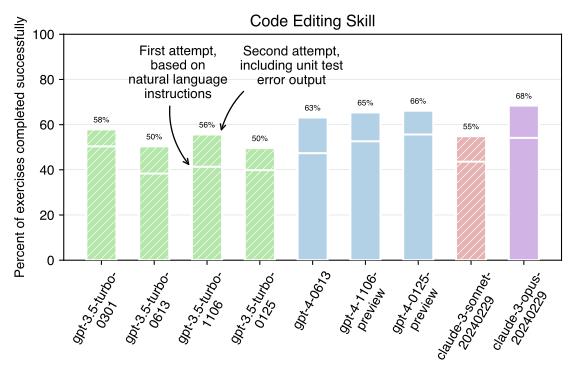
Claude 3 beats GPT-4 on Aider's code editing benchmark
Claude 3 Opus outperforms all of OpenAI's models on Aider's code editing benchmark, making it the best available model for pair programming with AI.
[
](https://aider.chat/2024/03/08/claude-3.html)
MAR 8, 2024
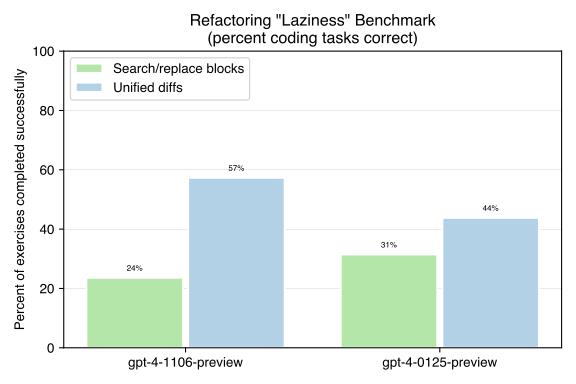
The January GPT-4 Turbo is lazier than the last version
The new `gpt-4-0125-preview` model is quantiatively lazier at coding than previous GPT-4 versions, according to a new "laziness" benchmark.
[
](https://aider.chat/2024/01/25/benchmarks-0125.html)
JAN 25, 2024
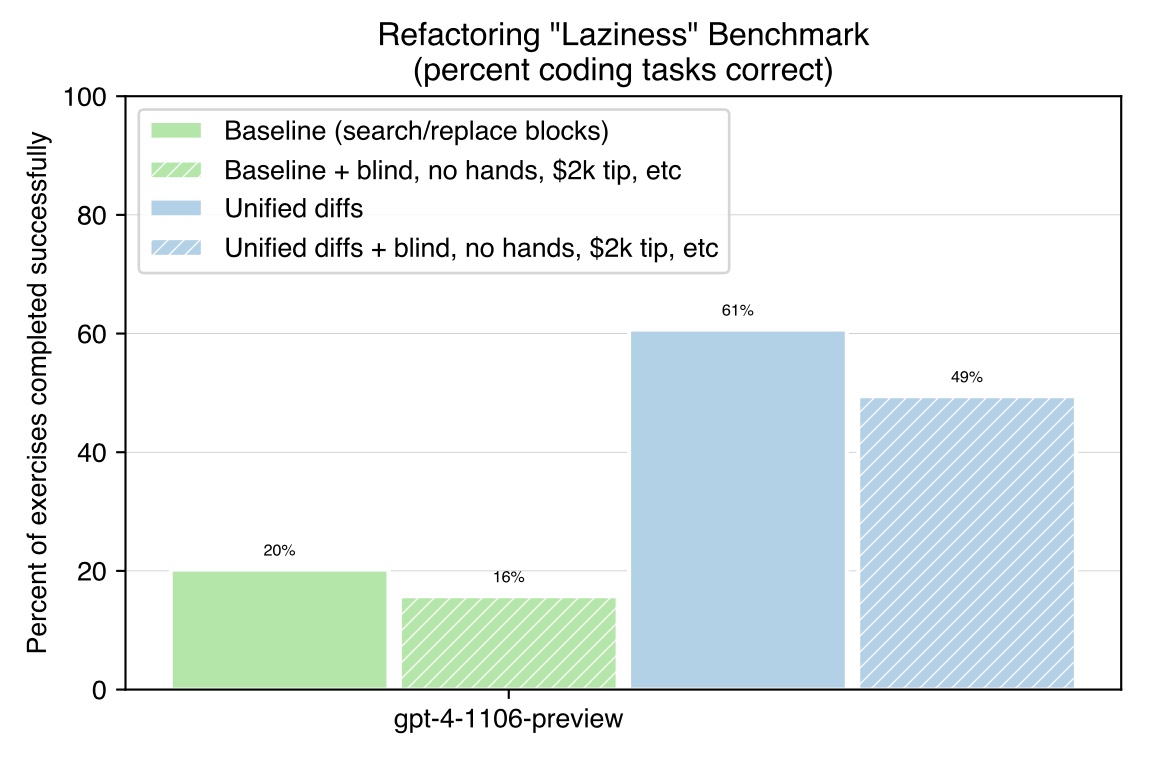
Unified diffs make GPT-4 Turbo 3X less lazy
GPT-4 Turbo has a problem with lazy coding, which can be signiciantly improved by asking for code changes formatted as unified diffs.
[
](https://aider.chat/2023/12/21/unified-diffs.html)
DEC 21, 2023
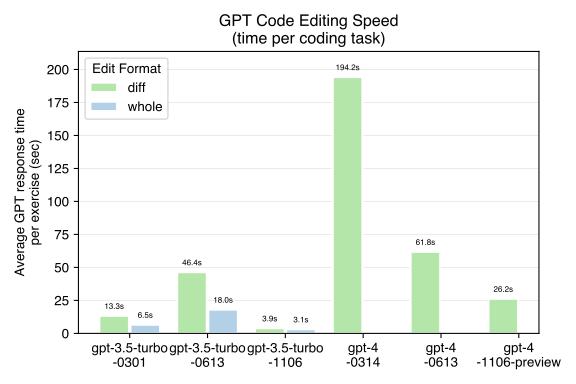
Speed benchmarks of GPT-4 Turbo and gpt-3.5-turbo-1106
This report provides a detailed comparison of the speed of GPT-4 Turbo and gpt-3.5-turbo-1106 models based on the aider benchmarking suite.
[
](https://aider.chat/2023/11/06/benchmarks-speed-1106.html)
NOV 6, 2023
Code editing benchmarks for OpenAI's "1106" models
A quantitative comparison of the code editing capabilities of the new GPT-3.5 and GPT-4 versions that were released in Nov 2023.
[
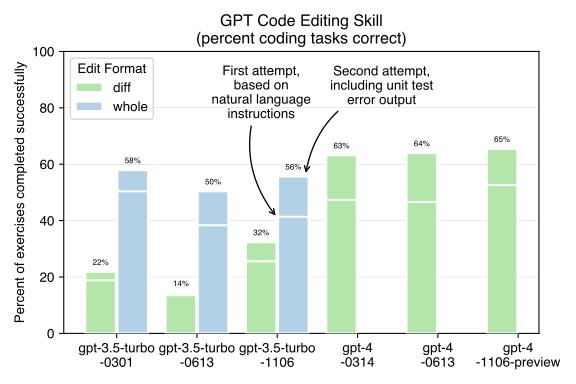
](https://aider.chat/2023/11/06/benchmarks-1106.html)
NOV 6, 2023
Building a better repository map with tree sitter
Tree-sitter allows aider to build a repo map that better summarizes large code bases.
[

](https://aider.chat/2023/10/22/repomap.html)
OCT 22, 2023
GPT code editing benchmarks
Benchmarking GPT-3.5 and GPT-4 code editing skill using a new code editing benchmark suite based on the Exercism python exercises.
[

](https://aider.chat/2023/07/02/benchmarks.html)
JUL 2, 2023
Improving GPT-4's codebase understanding with ctags
Using ctags to build a "repository map" to increase GPT-4's ability to understand a large code base.
[

](https://aider.chat/2023/05/25/ctags.html)
MAY 25, 2023